
Reading time: 10 minutes
Hello, data enthusiasts!
In our earlier explorations, we embarked on a journey to demystify AWS Kinesis in an insightful overview and delve into its architecture details.
Today, the curtain rises on a hands-on experience.
Armed with the wisdom from those discussions, we’ll use Amazon Kinesis, Terraform, Python, and the SDK to craft a dynamic data streaming application.
Before delving into this data streaming journey, make sure you have the essentials lined up. You’ll need Terraform, Python, and an AWS account with AWS CLI configuration. If you haven’t set these up yet, head over here for step-by-step instructions.
Let’s Walk Through the Tutorial Using These Steps:
- Provisioning Amazon Kinesis with Terraform
- Crafting Your Python Data Streamer with SDK Integration
- Consuming the Streamed Data
- Executing the code and seeing the results on the fly
- Bringing Your Data Streaming Solution to Life
- Destroy Your Stream to Avoid Unforeseen Charges
Provisioning Amazon Kinesis with Terraform
Let’s create a directory named “kinesis-with-sdk” and set the foundation.
Within “kinesis-with-sdk”, create the “main.tf” script, which serves as your cloud infrastructure blueprint. Feel free to modify the region and shard count within the script to align with your specific experiments.
Open the terminal and executes the terraform command below to initialize terraform:
terraform initAfter that, create your kinesis stream executing the command below:
terraform applyThe terraform will ask you to confirm. Type “yes” and go ahead.
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# aws_kinesis_stream.data_portfolio_stream will be created
+ resource "aws_kinesis_stream" "data_portfolio_stream" {
+ arn = (known after apply)
+ encryption_type = "NONE"
+ enforce_consumer_deletion = false
+ id = (known after apply)
+ name = "DataPortfolioStream"
+ retention_period = 24
+ shard_count = 1
+ tags_all = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
aws_kinesis_stream.data_portfolio_stream: Creating...
aws_kinesis_stream.data_portfolio_stream: Still creating... [10s elapsed]
aws_kinesis_stream.data_portfolio_stream: Still creating... [20s elapsed]
aws_kinesis_stream.data_portfolio_stream: Creation complete after 23s [id=arn:aws:kinesis:us-east-1:000000000000:stream/DataPortfolioStream]After that, in Kinesis AWS Console, you can visualize the stream created:

Crafting Your Python Data Streamer with SDK Integration
Time to use Python and craft our data streamer. Inside the “kinesis-with-sdk” directory, introduce “streamer.py” – your tool to send data records to Kinesis stream.
Explaining the most important parts of our streamer:
If you aren’t interested in code details, go for the next topic
Lines 1-3 : “import time” and “import boto3”.
These lines import the necessary Python libraries. “time” is used for introducing delays between data sending, and “boto3” is the AWS SDK for Python, allowing you to interact with AWS services.
Line 4: “from botocore.exceptions import NoCredentialsError”.
This line imports the “NoCredentialsError” class from the “botocore.exceptions” module. This exception is raised when AWS credentials are missing or incorrect.
Lines 6-7: “stream_name = “DataPortfolioStream” and “kinesis_client = boto3.client(‘kinesis’)”:
These lines defines the name of the Amazon Kinesis stream where you’ll send your data. Replace “DataPortfolioStream” with the actual name of your stream.
An instance of the Kinesis client is created using “boto3.client(‘kinesis’)”.
Line 10-21: “def send_data_with_sdk(data)”:
- This function is responsible for sending data to the Amazon Kinesis stream using the SDK. Inside the “send_data_with_sdk” function:
- The “try” block attempts to send a record to the Kinesis stream.
- The “put_record” method, on line 14, is called on the Kinesis client, which sends a single data record to the stream. The “StreamName” parameter specifies the target stream, “Data” contains the data to send (encoded in UTF-8), and “PartitionKey” determines the partition within the stream where the data will be placed.
- After sending the record, on line 19, information about the sent record, including the shard ID, is printed to the console.
On line 20-21: In the “except NoCredentialsError” block, if AWS credentials are missing or incorrect, a message is printed indicating that valid credentials are needed.
Line 24: “def main()”: This function serves as the entry point of the program. Inside the “main” function:
- A loop from 1 to 11 is used to send ten different messages to the Kinesis stream.
- For each iteration, a message is created using f-string formatting.
- The “send_data_with_sdk” function is called with the message as an argument.
- The “time.sleep(1)” line introduces a one-second delay between sending each message.
Lines 31-32: the final lines “if __name__ == “__main__”:” and “main()” ensure that the “main” function is executed when the script is run.
Our “streamer.py” demonstrates how to use the AWS SDK to send data records to an Amazon Kinesis stream.
It defines a function to handle the sending of data, iterates through a loop to send multiple messages, and prints out information about the sent records.
The script provides a foundation for building a data streaming solution that leverages Amazon Kinesis to manage and process real-time data flows.
Consuming the Streamed Data
But the journey doesn’t end with sending data.
Now, let’s consume the data! Create a new Python script name “consumer.py” within the “app” directory. This script reads data from the stream and processes it:
Explaining the most important parts of our consumer:
Same here, If you aren’t interested in code details, go for the next topic
Lines 9-34: “def consume_stream()”
This function orchestrates the process of consuming data from the Kinesis stream. Inside the “consume_stream” function:
- A “shard_iterator” is obtained using the “get_shard_iterator” method. The iterator specifies the shard from which you want to consume data and the iterator type (in this case, “”LATEST”);
- Entering a “while True” loop signifies that data consumption will continue indefinitely;
- The “get_records” method retrieves records using the current “shard_iterator”. The retrieved records are stored in the “records” variable.
- If there are no records, a message is printed indicating that no more records are available.
- For each record in the batch, the content of the “Data” field is extracted and displayed;
- The “shard_iterator” is updated using the value of “response[“NextShardIterator”]” (line 33) to continue retrieving records from where the previous batch left off;
- The “time.sleep(5)” introduces a 5-second pause before fetching the next batch of records. This helps in managing the consumption rate and avoiding excessive requests.
Lines 37-42: “def main()”
This function serves as the entry point of your program. Inside the “main” function the “consume_stream” function is called to initiate the data consumption process.
The lines “if __name__ == “__main__”:” and “main()” ensure that the “main” function is executed when the script is run.
Our “streamer.py” demonstrates how to use the AWS SDK to consume data records from an Amazon Kinesis stream.
It establishes a function to handle the consumption process, enters a loop to continually retrieve and process records, and maintains a steady pace by introducing time intervals between record retrieval.
The script forms the foundation for building a data streaming solution that utilizes Amazon Kinesis to receive and process real-time data streams.
Bringing Your Data Streaming Solution to Life
Now, it’s time to witness the magic unfold as we execute the “streamer.py” and “consumer.py” scripts.
This step-by-step guide will walk you through the process of running the code and witnessing real-time results as your data streams come to life.
Before we dive into execution, make sure you have completed the prerequisites mentioned earlier.
Start the Consumer
Begin by executing the “consumer.py” script.
This script initializes the consumer and establishes connections to the Kinesis stream’s shard. The consumer will be in a state to process incoming data.
python3 consumer.pyKeep an eye on the terminal where the consumer is running. You should see output indicating that the consumer is actively processing data, displaying the records it’s consuming from the stream after we initiaze the producer.
As the producer is not sending messages yet, you’ll see logs indicating the there is “No records to consume”.
Records size: 0
No records to consume.Running the Streamer
Open a new tab in your terminal and navigate to the “kinesis-with-sdk” directory. Here’s the command to execute the “streamer.py” script:
python3 streamer.pyAs you execute this command, you’ll notice the streamer script spring into action. It will start sending data records to the Amazon Kinesis stream you’ve set up. Keep an eye on your terminal as each message is sent with a one-second interval.
python3 streamer.py
Sending data message: Message 1...
Record sent via SDK. Data: Message 1. ShardId: shardId-000000000000
.
.
.
Sending data message: Message 10...
Record sent via SDK. Data: Message 10. ShardId: shardId-000000000000Observe the Results
With both the consumer and the streamer scripts running concurrently, you’ll witness a seamless flow of data. The consumer will process the records sent by the streamer in real-time, and you’ll be able to observe the consumption process as it happens. Look at your “consumer.py” terminal:
Records size: 0
No records to consume.
Records size: 2
Consumed: b'Message 1'
Consumed: b'Message 2'
Records size: 4
Consumed: b'Message 3'
Consumed: b'Message 4'
Consumed: b'Message 5'
Consumed: b'Message 6'
Records size: 4
Consumed: b'Message 7'
Consumed: b'Message 8'
Consumed: b'Message 9'
Consumed: b'Message 10'Exploration and Further Experimentation
As both the producer and consumer are active and connected, you now have the opportunity to experiment further with your data streaming solution. Modify the scripts, adjust the pace of data sending, and explore how different scenarios affect the data flow and processing.
Destroy Your Stream to Avoid Unforeseen Charges
Congratulations on successfully completing your hands-on journey with Amazon Kinesis, Terraform, Python, and SDK! As you conclude this experience, it’s important to ensure that you’re not leaving behind any remaining resources that could lead to unexpected charges down the line.
Navigate to “kinesis-with-sdk” folder and execute the terraform command below to destroy your stream:
terraform destroyThe terraform will ask you to confirm. Type “yes” and go ahead.
aws_kinesis_stream.data_portfolio_stream: Refreshing state... [id=arn:aws:kinesis:us-east-1:000000000000:stream/DataPortfolioStream]
Terraform used the selected providers to generate the following execution plan.
Resource actions are indicated with the following symbols:
- destroy
Terraform will perform the following actions:
# aws_kinesis_stream.data_portfolio_stream will be destroyed
- resource "aws_kinesis_stream" "data_portfolio_stream" {
- arn = "arn:aws:kinesis:us-east-1:000000000000:stream/DataPortfolioStream" -> null
- encryption_type = "NONE" -> null
- enforce_consumer_deletion = false -> null
- id = "arn:aws:kinesis:us-east-1:000000000000:stream/DataPortfolioStream" -> null
- name = "DataPortfolioStream" -> null
- retention_period = 24 -> null
- shard_count = 1 -> null
- shard_level_metrics = [] -> null
- tags = {} -> null
- tags_all = {} -> null
- stream_mode_details {
- stream_mode = "PROVISIONED" -> null
}
}
Plan: 0 to add, 0 to change, 1 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
aws_kinesis_stream.data_portfolio_stream: Destroying... [id=arn:aws:kinesis:us-east-1:000000000000:stream/DataPortfolioStream]
aws_kinesis_stream.data_portfolio_stream: Still destroying... [id=arn:aws:kinesis:us-east-1:000000000000:stream/DataPortfolioStream, 10s elapsed]
aws_kinesis_stream.data_portfolio_stream: Destruction complete after 12sAt Kinesis AWS Console, confirm that the resource was deleted:
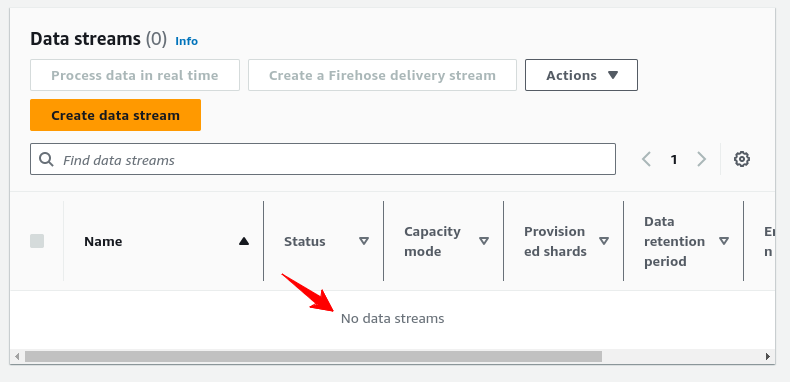
Bravo! You’ve completed this comprehensive data streaming tutorial, wielding Amazon Kinesis, Terraform, Python, and the SDK to set up, send, and consume data streams.
Armed with these newfound skills, you are now well-equipped to explore more advanced data streaming scenarios and embark on exciting data-driven journeys.
Happy coding and streaming! 🚀🎉
All the code used here is shared on my Github.
Credits:
Imagens from Freepik: Chef kneading bread dough in hands



{kind=link}
Permalink