
Tempo de leitura: 6 minutos
In the ever-evolving landscape of data processing, AWS Kinesis has emerged as a trailblazer, enabling businesses to harness the power of real-time data streaming.
This blog post delves into the intricate architecture of AWS Kinesis, exploring its core components, key concepts, and the seamless data flow from producers to consumers.
What you’ll see in this post:
- Understanding the Basics: Records, Partition Keys, and Shards
- Maximum Throughput and Scalability
- Data Flow: from Producer to Consumer
- Retaining and Reprocessing Data
- Correlation between Partitions and Shards
- A summary for AWS Certification
Understanding the Basics: Records, Partition Keys, and Shards
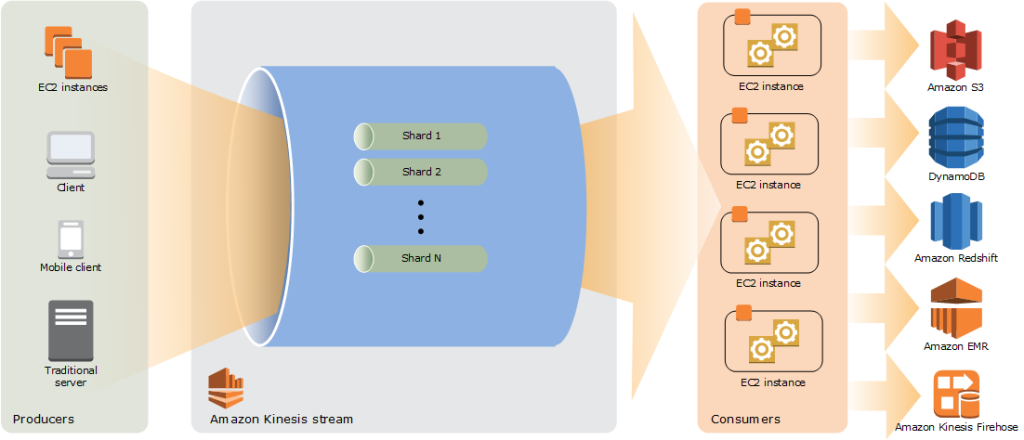
At the heart of AWS Kinesis are “records” – the fundamental units of data that are ingested, processed, and eventually consumed.
Each record represents a discrete piece of information and can be as small as a few bytes or as large as 1 MB. These records carry information that can range from log entries to sensor readings, and their collective flow forms the data stream.
To ensure efficient distribution and parallel processing of records, AWS Kinesis employs the concept of “shards”. Each shard is a unit of data distribution, and it can be thought of as a mini-stream within the larger data stream.
Records within a shard are ordered based on their sequence numbers, allowing you to maintain the integrity and chronological order of the data.
Partition keys play a pivotal role in this architecture. When a producer sends a record to AWS Kinesis, it attaches a partition key to the record. This key determines the shard to which the record is assigned.
Consequently, records with the same partition key are guaranteed to land in the same shard, enabling you to maintain the order and relationship between related data points.
Maximum Throughput and Scalability
Shards define the maximum throughput that a data stream can handle. Each shard has a defined maximum write and read capacity.
For instance, a shard can handle up to 1 MB/s of data input accommodating up to 1,000 records per second and it can handle 2 MB/s of data output (shared between all consumers) in provisioned mode.
However, it’s important to note that a data stream’s total capacity scales linearly with the number of shards.
This elasticity allows you to adjust your data stream’s capacity to accommodate fluctuating data rates.
Data Flow: from Producer to Consumer
Imagine a scenario where IoT devices are producing a continuous stream of sensor readings. These readings are sent by producers to a Kinesis Data Stream.
The producer attaches a partition key to each reading, ensuring that related data points are grouped together.
Once in the Kinesis Data Stream, the records are automatically distributed across shards based on their partition keys. The data can then be processed in real-time using Kinesis Data Analytics, where SQL queries can be applied to derive insights from the streaming data.
But the journey doesn’t end there. Kinesis Data Firehose steps in to deliver the processed data to various destinations.
Whether it’s archiving the data in Amazon S3, feeding it into Amazon Redshift for further analysis, or populating Elasticsearch for real-time search, Kinesis Data Firehose simplifies the data delivery process.
Retaining and Reprocessing Data
The retention period of a record in a Kinesis Data Stream is the length of time that the data records are accessible after they are added to the stream.
By default, a Kinesis data stream stores records for 24 hours. However, you can increase the retention period up to 8760 hours (365 days).
After this period, the data is automatically removed from the shard, ensuring that the architecture remains efficient and unburdened by unnecessary data.
But what if you need to reprocess the data? This is where the immutability of data in AWS Kinesis comes into play. Once a record is written to a shard, it becomes immutable and cannot be modified.
This ensures data consistency and integrity, critical for maintaining accurate historical records.
Correlation between Partitions and Shards
A key concept to understand is that the number of shards defines the parallelism of your architecture. Partitions and partition keys provide the means to distribute data efficiently across these shards.
The careful selection of partition keys allows you to optimize data distribution and achieve efficient processing.
A summary for AWS Certification
In addition to the general information provided above, there are a few additional concepts that are important for AWS certification:
Records: A record is the basic unit of data in Kinesis. A record consists of a sequence number, a partition key, a data payload, and optional metadata.
Partition key: The partition key is used to distribute records across shards. Kinesis ensures that all records with the same partition key are processed by the same shard.
Maximum throughput for each shard: The maximum throughput for each shard is 1 thousand records per second per shard.
Tools that can be used in this process: AWS SDK, Kinesis Client Library (KCL), the Kinesis Data Analytics API, and the Kinesis Firehose service.
Retention: Kinesis data is retained for 24 hours by default. You can increase the retention period up to 365 days.
Reprocessing data: You can reprocess data in Kinesis by using the Kinesis Data Analytics API or the Kinesis Firehose service.
Immutability: Kinesis data is immutable. This means that once data is written to Kinesis, it cannot be changed.
Correlation between partition and shards: Each shard is associated with a single partition key. This means that all records with the same partition key are processed by the same shard.
Ordering: Kinesis data is ordered by shard and sequence number. This means that consumers can read data in the same order in which it was produced.
At the end
From the moment data is produced to when it’s consumed and analyzed, AWS Kinesis orchestrates a sophisticated symphony of components and concepts.
Its architecture, built around records, shards, partition keys, and the interconnected tools like Data Analytics and Data Firehose, empowers businesses to harness real-time insights at scale.
By seamlessly handling data retention, reprocessing, and maintaining data immutability, AWS Kinesis ensures that your streaming data architecture is not only high-performing but also reliable and secure.
As you embark on your journey into the realm of real-time data processing, AWS Kinesis stands as a steadfast companion, opening doors to new opportunities and transformative insights.
That’s all folks!
Sources:
Amazon Kinesis Data Streams Terminology and Concepts
Everything About Kinesis Data Analytics Explained in Five Minutes
Managed Streaming Data Service – Amazon Kinesis Data Streams FAQs – AWS
Retaining data streams up to one year with Amazon Kinesis Data Streams | AWS Big Data Blog
Changing the Data Retention Period – Amazon Kinesis Data Streams
What I miss in Amazon Kinesis Video Streams? | AWS Maniac
Credits:
Imagens from: Amazon Kinesis Data Streams



{kind=link}
[…] In our earlier explorations, we embarked on a journey to demystify AWS Kinesis in an insightful overview and delve into its architecture details. […]